
tg-me.com/knowledge_accumulator/177
Last Update:
Meta-Learning Bidirectional Update Rules [2021] - обучаем бэкпроп
На мой взгляд, за мета-обучением будущее, но обучаемый алгоритм не должен содержать много параметров, чтобы не переобучиться на мета-трейне. На днях наткнулся на данную работу, предлагающую свой вариант мета-параметризации.
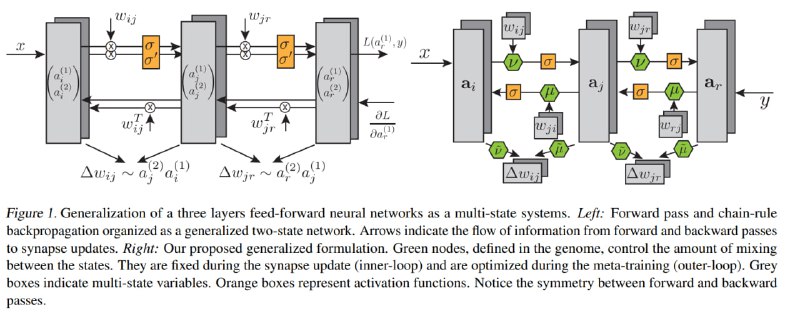
Рассмотрим полносвязную нейросеть в такой перспективе: у каждого нейрона есть 2 "канала" - для forward и backward. Мы сначала совершаем цепочку расчётов по первому каналу нейрона слева направо, далее считаем градиент ошибки по последнему слою, и по второму каналу совершаем цепочку расчётов справа налево. Это будет градиент, который мы потом с некоторым learning rate применим к весам. Это на картинке слева. Обобщаем это следующим образом:
1) Теперь у каждого нейрона K "каналов", причём они не независимы, и суммируются все со всеми и в forward, и в backward, и даже в weights update. Но мы обучаем несколько матриц K x K, используемые как веса при суммировании из каждого в каждый канал во всех этапах.
2) Добавим мета-параметры, похожие на momentum и learning rate
3) На вход первому слою будем подавать как обычно input, а последнему просто правильный ответ, чтобы алгоритм сам обучился тому, как обновлять параметры
Теперь эти ~O(K^2) параметров можно обучать, оптимизируя производительность на валидационном датасете. Обучать их можно как генетикой, так и напрямую градиентным спуском, если модель обучать не так много шагов.
Если подумать, схема похожа на ту же VSML, с разницей в том, что здесь авторы строят свою модель именно как обобщение схемы forward-backward, из-за чего возникает много лишней нотации и слегка переусложнённых конструкций. Авторы указывают, что в их работе нет RNN, но это различие скорее в интерпретации происходящего. Глобальная логика та же - обучаемые небольшие матрицы регулируют пробрасывание информации по архитектуре, а также обновление содержащейся в ней памяти, именуемой весами.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/177